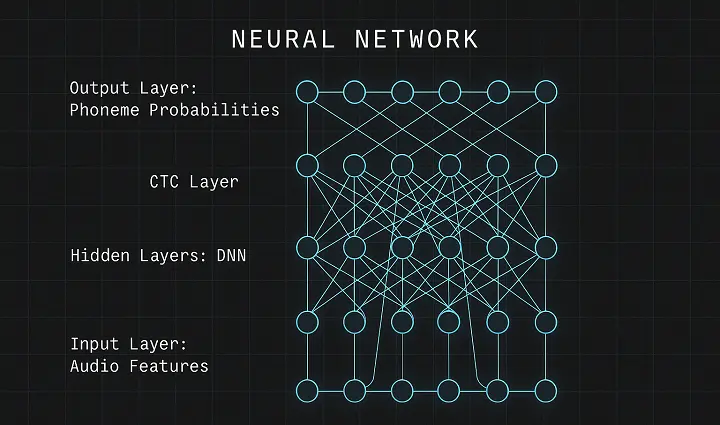
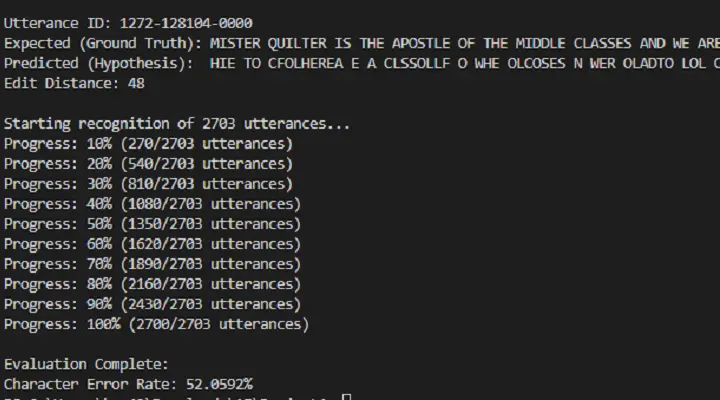
A full-stack, end-to-end speech recognition system implementing Connectionist Temporal Classification (CTC) and deep neural networks to convert raw audio into transcribed text. The system supports variable-length input and output sequences, and is currently being extended to serve predictions through an API and web interface.
Key Components
- Input Processing: Extracts audio features using context windows and subsampling for performance and generalization.
- Neural Architecture: Deep feed-forward acoustic model trained with TensorFlow and ReLU activations.
- CTC Alignment: Implements dynamic programming to align input frames with output token sequences.
- Beam Search Decoding: Generates final predictions using beam search and computes Character Error Rate (CER) for evaluation.
- Deployment (in progress): Building API endpoints and frontend interface to expose transcription capabilities.
- StackPython, TensorFlow, NumPy, kaldi-io, REST API (WIP)
- SourceGithub